The control plane for AI inside your organisation
Provision Claude or ChatGPT to every employee, pre-configured, audited, and on budget.
Includes $20 in free OpenAI, Anthropic and Google credits
Dashboard
Roll out capabilities to teams and manage devices.
Tool call activity
MCP proxy successes & errors by day






Deploy AI to your whole team, faster than ever
Provision
Ship our Harriet Desktop app, Claude, or ChatGPT to every employee with the right scope for each role. Bundle skills, knowledge, and tools into profiles, then assign by team in one click, with no per-user setup.

Connect
Plug AI into Workday, Salesforce, SharePoint, and every system your business already runs on. Pre-built MCP connectors or bring your own, so AI sees the right data for the right person.
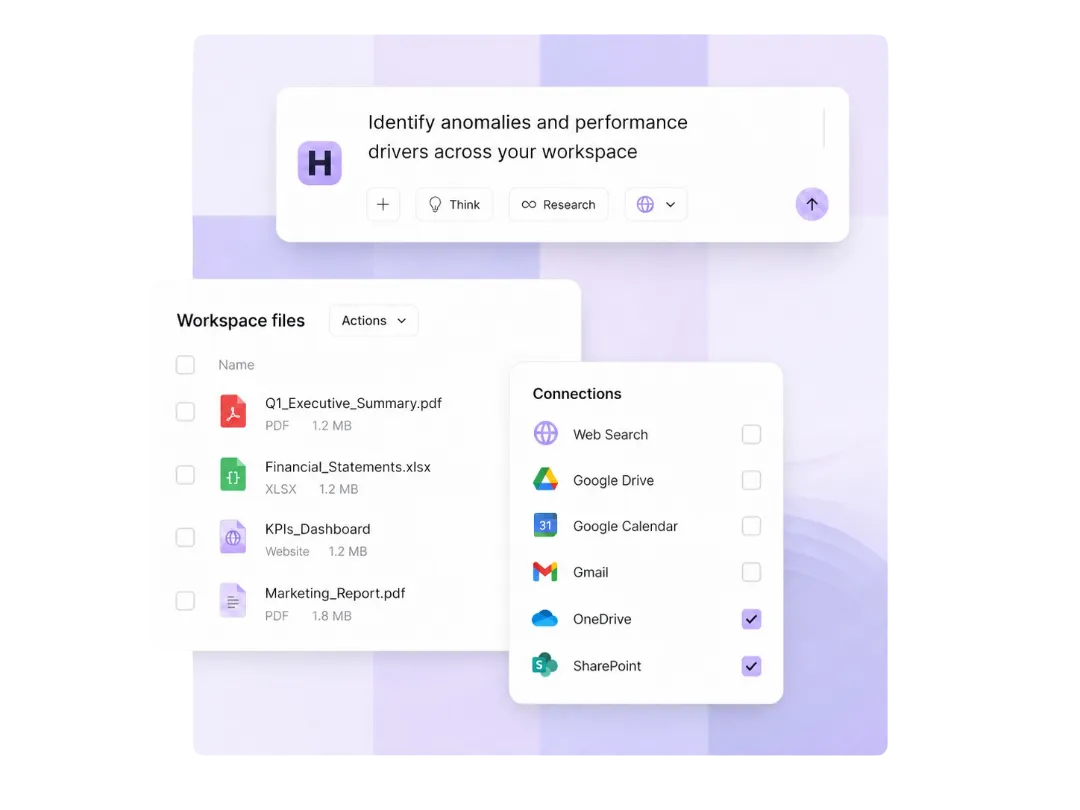
Share
Any team can build a skill or wire up a custom MCP. Those go into the shared library, so every other team in the company can use them instantly. Build once. No duplication. No rebuilding from scratch.
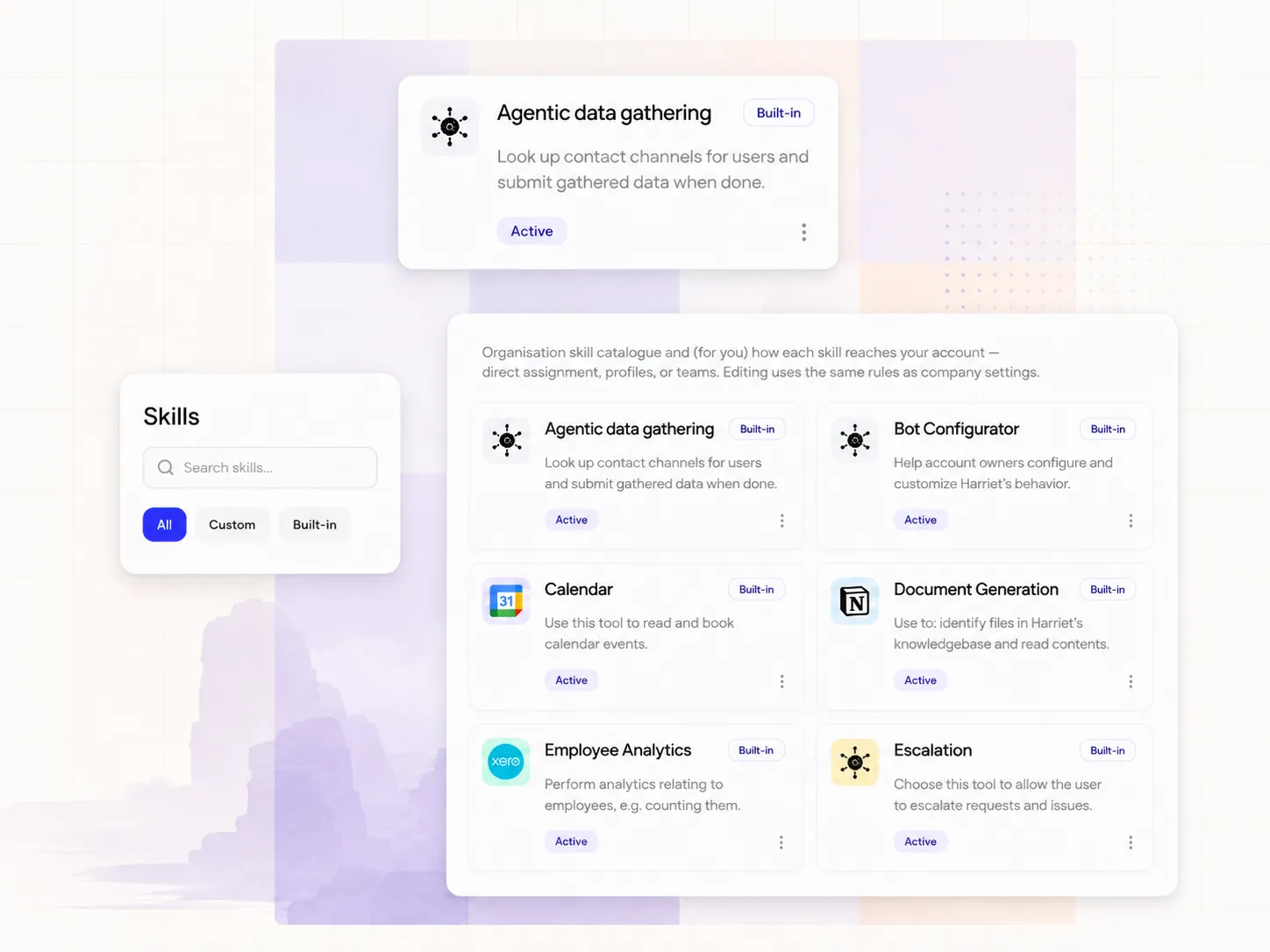
Audit
Every prompt, tool call, and approval logged with the user, team, model, and skill behind it. Hand Legal or your CISO a clean audit trail on demand, not weeks later.
Manage spend
Track model usage, per-team burn, and ROI by outcome in one dashboard. Set hard caps or soft alerts per team or skill, and stop runaway LLM costs before they happen.

AI-powered work environment
Provision Claude, ChatGPT or our own app Harriet Desktop. Chat, search, analyse, and create - all your work in one connected hub, with the flexibility of choosing any model provider your team wants.
$20 across OpenAI, Anthropic and Google
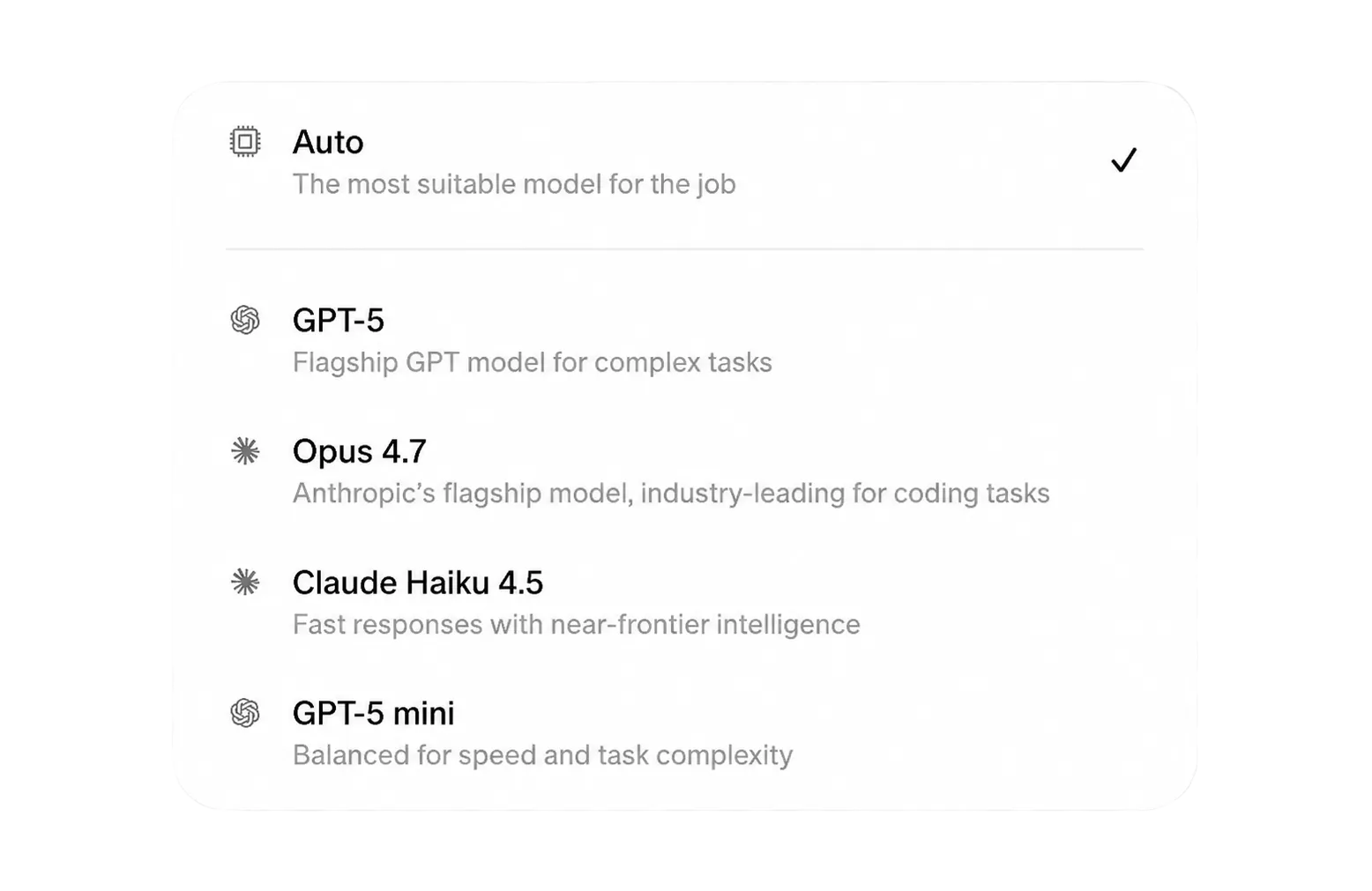
Save on your AI bill, don't compromise on quality.
- Per-device model policy
- One bill, full audit trail
- Bring your own keys, or use Managed Credits
Businesses are shipping AI without dedicated departments
Using Harriet, a 500-person US education software company shipped AI to every team, without a dedicated AI department.
Get started now
Connect up to 3 devices for free and test with your team.
$20 across OpenAI, Anthropic and Google







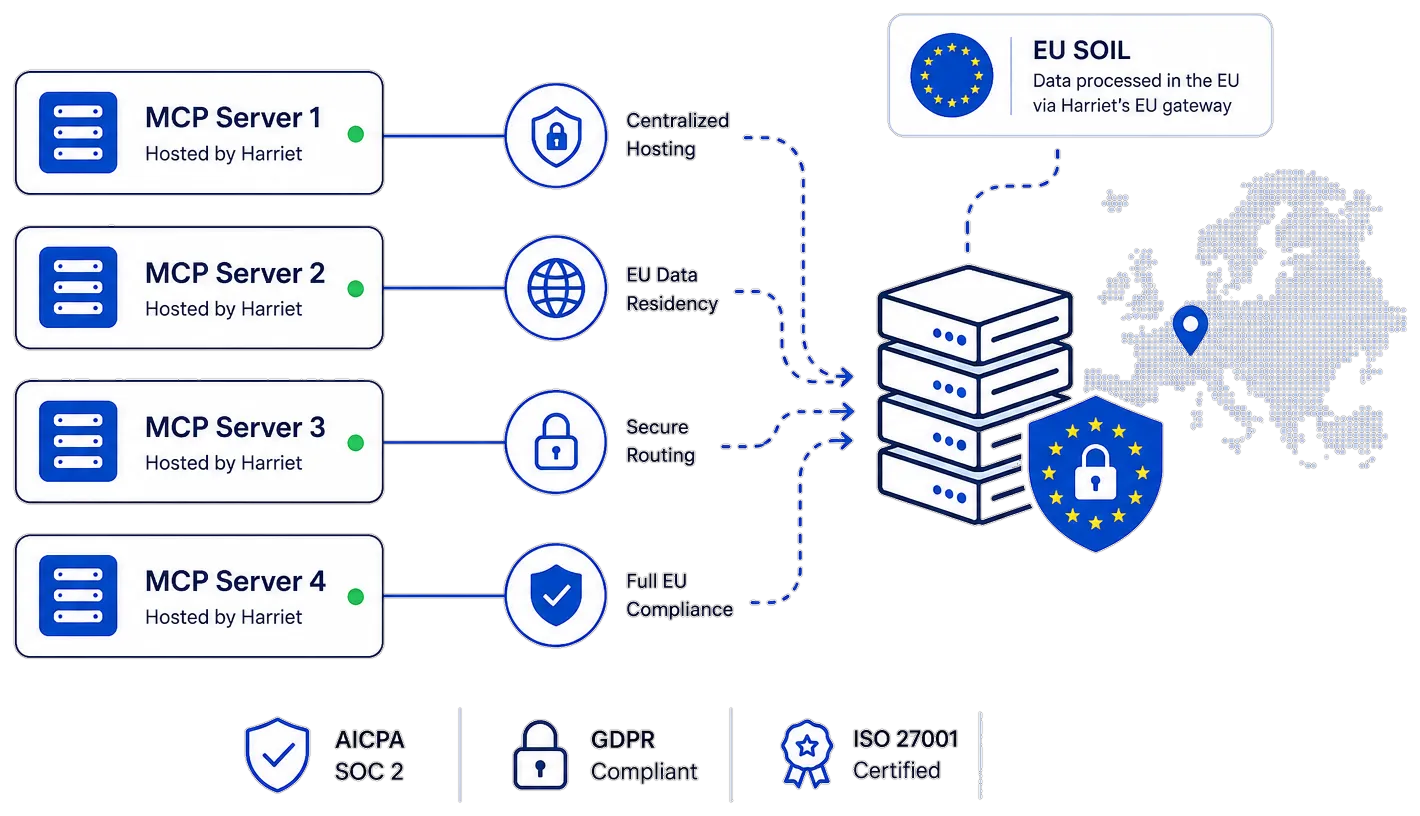
Enterprise-grade
The controls your CISO already asked for.
SOC 2 certified with per-user permissions on every tool you connect. AI requests are processed by contracted LLM sub-processors under our DPA — your data is not used to train models.